
获取元素的最终background-color
// 作用是将连字符类的css属性值,转换成驼峰写法。
function camelize (str) {
return str.replace(/-(\w)/g, function (strMatch, newStr) {
return newStr.toUpperCase();
});
}
// 获取特定元素的计算样式
function getStyle (ele, property) {
if (!ele || !property) {
return false;
}
// 获取元素的值
var defaultValue = ele.style[camelize(property)]
var css = null;
// 如果获取不到元素的值呢就执行
if (!defaultValue) {
if (document.defaultView && document.defaultView.getComputedStyle) {
css = document.defaultView.getComputedStyle(ele, null);
// 方法IE9+以及其他现代浏览器都支持 getPropertyValue
// IE6~8是不支 getComputedStyle
defaultValue = css ? css.getPropertyValue(property) : null
}
}
return defaultValue;
}
// 检查获取背景色的有效性
function checkBgColor (ele) {
var defaultValue = getStyle(ele, 'background-color');
// 判断是否是颜色
var hasColor = defaultValue ? true : false;
// 排除特殊情况
if (defaultValue === 'transparent' || defaultValue === 'rgba(0, 0, 0, 0)') {
// 未设置background-color,或者设置为跟随父节点
hasColor = false;
}
else if (getStyle(ele, 'opacity') === '0' || getStyle(ele, 'visibility') === 'hidden' || getStyle(ele, 'display') === 'none') {
// dom节点透明度为全透明
hasColor = false;
}
else {
hasColor = true
}
return hasColor;
}
// 检测父节点 这里检测父节点主要是针对父节点设置了隐藏属性(display:none;visibility:hidden;)
function checkParent (ele) {
// 获取父节点
var parant = ele.parentNode;
// 是否有颜色
var hasColor = true;
//一般来说是不会把body设为隐藏
if (parant.nodeName === 'BODY') {
return hasColor
}
if (getStyle(parant, 'display') === 'none' || getStyle(parant, 'visivility') === 'hidden') {
hasColor = false;
}
else {
hasColor = true;
}
return hasColor;
}
//获取最终颜色
function getRGB (ele) {
//如果父元素为隐藏,就不用再获取元素
if (!checkParent(ele)) {
return ''
}
// 如果有元素就返回元素颜色
if (checkBgColor(ele)) {
return getStyle(ele, 'background-color')
}
else if (ele !== document.documentElement) {
console.log(getRGB(ele.parentNode))
return getRGB(ele.parentNode);
}
}
zepto和jquery的区别?
Zepto:
- Zepto更轻量级
- Zepto是JQuery的精简版,针对移动端去除了大量JQuery的兼容代码
- 部分API的实现方式不同
详情:
- 1.针对移动端程序,Zepto有一些基本的触摸事件可以用来做触摸屏交互(tap事件、swipe事件),Zepto是不支持IE浏览器的。
- 2.DOM操作的区别:添加id时jQuery不会生效而Zepto会生效
- 3.事件触发的区别:使用jQuery时load事件的处理函数不会执行,使用zepto时load事件的处理函数会执行。
- 4.事件委托的区别:zepto中,选择器上所有的委托事件都依次放入到一个队列中,而在jquery中则委托成独立的多个事件
- 5.width() 与 height()的区别:zepto由盒模型(box-sizing)决定,用.width()返回赋值的width,用.css(‘width’)返回border等的结果;jquery会忽略盒模型,始终返回内容区域的宽/高(不包含padding、border).
- 6.offset()的区别:zepto返回{top,left,width,height}; jquery返回{width,height}。zepto无法获取隐藏元素宽高,jquery可以
- 7.zepto中没有为原型定义extend方法而jquery有(extend() 函数用于将一个或多个对象的内容合并到目标对象。)
- 8.zepto的each方法只能遍历数组,不能遍历JSON对象
主流JS设计模式简单分解
- 观察者模式与发布订阅模式如何区分?
observer vs pub/sub
- pub/sub ==> 是根据topic 比如click等来执行通知
- observer ===> 比如 redux.subscribe的api就是这样子不会对事情做区分 [‘日志’,’发起请求’,’UI’].forEach(fn)
2.单例模式应用场景
dialog或者modal组件
button => click => 弹出modal、dialog ==> 点击叉叉隐藏
decorator装饰者模式
这个模式就是在原有的对象上装饰更多行为,并且保持变量名不变
用过ES7的@decorator或者python等语言的,应该对decorator不陌生
一个简单的装饰者模式代码实践
```html //日志系统 decorator var decorator_log = function (fn) { return function () { var result = fn.apply(this, arguments); console.log(‘日志系统,加法计算参数是– ‘); console.log(arguments[0])
return result } }
// 主功能 var Add = function (array) { return array.reduce(function (pre, cur) { return pre + cur; }, 0); }; Add = decorator_log(Add); var data=[0]; $(‘#d-btn’).click(function () { var nextData = data.length data.push(nextData) $(‘#decorator span’).html(Add(data,nextData)); $(‘#d-btn span’).html(nextData); })
### observer [观察者模式]
根据状态的变化主动触发观察者队列、hashMap的回调行为一个简单的观察者模式代码实践(改变其内部的变化会被观察者监听到)
简单的对象回调数组演示
```html
// 创建一个 observer的服务
var Observerable = function () {
// 订阅者订阅的方法
this.observer = [];
// 方法的参数
this.data = [];
}
// 设置订阅者方法
Observerable.prototype.subscribe = function (ObserverFn) {
this.observer.push(ObserverFn);
}
// 设置发布者方法
Observerable.prototype.digest = function (ObserverFn) {
var data = this.data;
// 通知所有注册该数据源的回调处理
this.observer.forEach(function (observer) {
observer(data)
});
}
// 观察者模式 ==> 数据源一致 ==> 通知所有注册该数据源的回调处理
var observer1 = function (data) {
var value = data.reduce(function (pre, cur) {
return pre + cur;
}, 0);
$('#pub-sub span').html('数据总和为' + value);
};
var observer2 = function (data) {
$('#ps-btn span').html(data[data.length - 1]);
}
// 初始化observer的服务
var observerable_inst = new Observerable();
// 设置订阅者
observerable_inst.subscribe(observer1);
observerable_inst.subscribe(observer2);
// 设置发布者
observerable_inst.change = function (val) {
this.data.push(val)
// 通知所有注册该数据源的回调处理
observerable_inst.digest();
}
$('#ps-btn').click(function(){
var randomNum = Math.floor(Math.random() * 100);
observerable_inst.change(randomNum);
})
publish/subscribe [订阅发布模式]
在代码模块的共享访问空间存储hashMap的topic/callback形式 添加on/off/trigger等接口实现挂载、移除、触发等动作
结合事件进行的订阅发布模式
var PubSub = function () {
// //存储事件映射表(事件池)
this.eventPool = {}
}
// 移除
PubSub.prototype.off = function (topicName) {
delete this.eventPool[topicName];
}
// 挂载
PubSub.prototype.on = function (topicName, callback) {
var topic = this.eventPool[topicName];
// 如果没有该事件就创建一个
if (!topic) {
this.eventPool[topicName] = []
}
// 存储该事件
this.eventPool[topicName].push(callback)
}
// 触发
PubSub.prototype.trigger = function () {
// 转换为数组
var _arg = [].slice.call(arguments);
// 获取到需要触发事件的名称
var topicName = _arg.shift();
// 回调方法传入的参数
var callbackArg = _arg
// 获取回调方法
var topicCallback = this.eventPool[topicName];
// 遍历触发回调方法
if (topicCallback) {
topicCallback.forEach(function (callback) {
callback.apply(this, callbackArg)
})
}
}
// 初始化发布/订阅方法
var pubSub = new PubSub();
// 挂载一些动作
pubSub.on('click', function (data) {
$('#ps-btn span').html(data[data.length - 1]);
});
pubSub.on('click', function (data) {
var value = data.reduce(function (pre, cur) {
return pre + cur;
}, 0);
$('#pub-sub span').html(value);
});
var data = [0];
$('#ps-btn').click(function(){
var randomNum = Math.floor(Math.random() * 100);
data.push(randomNum);
// 触发动作
pubSub.trigger('click',data);
})
singleton[单例模式]
构造函数的实例只有一个,一般是通过闭包存储内部实例,通过接口访问去访问内部实例(每一个实例的指向是相同的)
内存管理之单例模式
// 单例方法
// 单例方法
var singleton = function () {
var instance;
// 创建实例
var createInstance = function () {
this.a = 1;
this.b = 2;
}
// 获取实例
return {
getInstance: function () {
if (!instance){
// 创建一个实例
instance = new createInstance();
}
return instance
}
}
}
var test = singleton();
console.log(test.getInstance() == test.getInstance() )//true
mixin混合模式
这个模式和decorator装饰者模式有点类似,只是它的功能更加垂直。
相比于extends、Object.assign等方法,mixin模式更富有表现力。
mixin模式不能一概而论,可能依据不同的数据类型有不同的mixin策略,比如vue.mixin
一个简单的混合模式代码实践
class StateTracker {
constructor () {
this.raw = {
a: 1,
b: 2
}
}
// 混合模式方法入口
mixin (obj) {
Object.assign(this.raw, obj)
}
}
工厂模式
- 主要好处就是可以消除对象间的耦合,通过使用工程方法而不是new关键字。将多有实例化的代码集中在一个位置防止代码重复
- 工厂模式解决了重复实例化的问题,但还有一个问题,那就是识别问题,因为根本无法搞清楚他们到底是哪个对象的实例
function createObject (name, age, profession) {
var obj = new Object(); // 集中实例化的函数
obj.name = name;
obj.age = age;
obj.profession = profession;
obj.move = function () {
return this.name + ' at ' + this.age + ' engaged in ' + this.profession;
};
return obj;
}
var test1 = createObject('trigkit4',22,'programmer'); //第一个实例
var test2 = createObject('mike',25,'engineer');//第二个实例
console.log(test1);
console.log(test2);
构造函数模式
- 使用构造函数的方法,即解决了重复实例化的问题,又解决了对象识别的问题,该模式与工厂模式的不同之处在于
- 不使用new调用构造函数
- 创建对象的实例方法不引用this
所以构造函数适合在禁用this和new的环境中使用(或者说设计的出发点)。
function Person (name,age,job) {
var o = new Object();
// public members
o.sayName = function () {
console.log(name)
};
// private members
var nameUC = name.toUpperCase();
o.sayNameUC = function() {
console.log(nameUC)
};
return o;
}
var person = Person("Nicholas", 32, "software Engineer");
// public members
person.sayName(); // "Nicholas"
// private members
person.sayNameUC(); // "NICHOLAS"
meta viewport原理
它通过一个meta标签去控制窗口的大小宽度信息,具体有: width: 控制viewport的大小,可以指定的一个值。 height:和width相比较,指定高度。 initial-scale:初始缩放比例,当前第一次load的时候缩放的比例 maximum-scale:允许用户缩放到的最大比例 minimum-scale:允许用户缩放到的最小比例。 user-scalable:用户是否可以手动缩放
域名发散
PC 时代为了突破浏览器的域名并发限制,遵循这样一条定律: http静态资源采用多个子域名,目的是充分利用现代浏览器的多线程并发下载能力。
域名收敛
将静态资源放到一个域名下面,而非发散情况下的多域名下。域名发散是 PC 时代的产物,而现在进入移动互联网时代,通过无线设备访问网站,App的用户已占据了很大一部分比重,而域名收敛正是在这种情况下提出的。
在 PC 上,我们采用域名发散策略,是因为在 PC 端上,DNS 解析通常而言只需要几十 ms ,可以接受。而移动端,2G 网络,3G网络,4G网络/wifi 强网,而且移动 4G 容易在信号不理想的地段降级成 2G ,通过大量的数据采集和真实网络抓包分析(存在DNS解析的请求),DNS的消耗相当可观。因为在增加域的同时,往往会给浏览器带来 DNS 解析的开销。所以在这种情况下,提出了域名收敛,减少域名数量可以降低 DNS 解析的成本。
单纯在移动端采用域名收敛并不能很大幅度的提升性能,最重要的一点是,移动端建连的消耗非常大,而SPDY协议可以完成多路复用的加密全双工通道,显著提升非wifi环境下的网络体验。
display:inline-block 和float:left 的区别
display是指显示状态,float是针对块元素的浮动
使用inline-block:控制元素的垂直对齐跟横向排列元素。
使用浮动:
1、让元素环绕某一个元素,对一个元素跟围绕他的一些元素进行更多控制
2、不想处理inline-block带来的空白问题,元素浮动后,它会变为 inline-block。其宽度不是100%
首屏,白屏时间如何计算
A:加载完静态资源后通过ajax请求去后台获取数据,数据回来后渲染内容 html开头 -》css文件加载 -》 html内容 -》js文件加载 -》ajax请求 -》 渲染内容
在每个点打上一个时间戳,首屏时间 = 点8 – 点1;
B:使用后台直出,返回的html已经带上内容了
html开头 -》css文件加载 -》html内容 -》js文件加载
此时首屏时间 = 点4 – 点1。
-
细节1:js结束时间 – js开始时间 ≠ js的加载时间 因为 加载是并行的,执行是串行的结果。html开始加载的时候,浏览器会将页面外联的css文件和js文件并行加载,如果一个文件还没回来,它后面的代码是不会执行的。我们阻塞了css文件几秒,此时js文件因为并行已经加载回来,但由于css文件阻塞住,所以后面 JsStartTime 的赋值语句是不执行的!当我们放开阻塞,此时才会运行到 JsStartTime 的赋值、js文件的解析、JsEndTime的赋值,由于js时间加载早已完成,所以 JsEndTime 和 JsStartTime 的差值非常小。
-
细节2:html里面外联的js文件,前一个文件的加载会阻塞下一个文件的执行;而如果a.js负责渲染并会动态拉取js、拉取cgi并做渲染,会发现它后面的js文件再怎么阻塞也不会影响到它的处理
-
细节3:如果html的返回头包含chunk,则它是边返回边解析的,不然就是一次性返回再解析。这个是在服务器配置的
-
细节4:写在html里面的script节点的加载和解析会影响 domContentLoaded 事件的触发时间
Ajax readyState的五种状态
-
0 为初始化 还没有调用send()方法
此阶段确认XMLHttpRequest对象是否创建,并调用open()方法进行初始化准备。值为0表示对象已经存在,否则浏览器会报错 对象不存在 -
1 载入 已调用send()方法,正在发送请求
此阶段对XMLHttpRequest对象进行初始化,既调用open()方法,根据参数(method, url,true)完成对象状态的设置。并调用send()方法开始向服务器发送请求。 -
2 send()方法执行完成,并为下一阶段对数据解析作好准备。
此阶段接收服务器端响应的数据。但获得的还只是服务器端响应的原始数据,并不能直接在客户端使用。 -
3 正在解析响应内容
此阶段解析接收到的服务器端响应数据。即根据服务器端响应头部返回MIME类型吧数据转换成能通过responseBody、responseText或responseXML属性存取的格式。为在客户端调用作好准备。 -
4 响应内容解析完成,可以在客户端调用了
此阶段确认全部数据都已经解析为客户端可用的格式,解析已经完成。
AJAX状态码说明
100——客户必须继续发出请求
101——客户要求服务器根据请求转换HTTP协议版本
200——交易成功
201——提示知道新文件的URL
202——接受和处理、但处理未完成
203——返回信息不确定或不完整
204——请求收到,但返回信息为空
205——服务器完成了请求,用户代理必须复位当前已经浏览过的文件
206——服务器已经完成了部分用户的GET请求
300——请求的资源可在多处得到
301——删除请求数据
302——在其他地址发现了请求数据
303——建议客户访问其他URL或访问方式
304——客户端已经执行了GET,但文件未变化
305——请求的资源必须从服务器指定的位置得到
306——前一版本HTTP中使用的代码,现行版本中不再使用
307——申请请求的资源临时性删除
400——错误请求,如语法错误
401——请求授权失败
402——保留有效ChargeTo头响应
403——请求不允许
404——没有发现文件、查询、URL
405——用户在Request-Line字段定义的方法不允许
500——服务器产生内部错误
501——服务器不支持请求的函数
502——服务器暂时不可用,有时是为了防止发生系统过载
503——服务器过载或暂停维修
504——关口过载
505——服务器不支持或拒绝支请求头中指定的HTTP版本
Ajax如何实现
var xmlhttp;
function loadXMLDoc(url)
{
xmlhttp=null;
if (window.XMLHttpRequest)
{// code for all new browsers
xmlhttp=new XMLHttpRequest();
}
else if (window.ActiveXObject)
{// code for IE5 and IE6
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
if (xmlhttp!=null)
{
xmlhttp.onreadystatechange=state_Change;
xmlhttp.open("GET",url,true);
xmlhttp.send(null);
}
else
{
alert("Your browser does not support XMLHTTP.");
}
}
function state_Change()
{
if (xmlhttp.readyState==4)
{// 4 = "loaded"
if (xmlhttp.status==200)
{// 200 = OK
// ...our code here...
}
else
{
alert("Problem retrieving XML data");
}
}
}
JSONP 的工作原理
利用 < script > 标签没有跨域限制的“漏洞”来达到与第三方通讯的目的。当需要通讯时,本站脚本创建一个 < script >元素,地址指向第三方的API网站,如: 并提供一个回调函数来接收数据。
第三方产生的响应为json数据的包装(故称之为jsonp,即json padding)形如:callback({“name”:”hax”,”gender”:”Male”}) 这样浏览器会调用callback函数,并传递解析后json对象作为参数。本站脚本可在callback函数里处理所传入的数据。
前端解决跨域问题的8种方案
1.document.domain + iframe (只有在主域相同的时候才能使用该方法)
2.动态创建script
3.location.hash + iframe
4.window.name + iframe
5.postMessage(HTML5中的XMLHttpRequest Level 2中的API)
6.CORS 使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。
7.使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。
8.web sockets web sockets原理:在JS创建了web socket之后,会有一个HTTP请求发送到浏览器以发起连接。取得服务器响应后,建立的连接会使用HTTP升级从HTTP协议交换为web sockt协议。
get和post的区别
HTTP的底层是TCP/IP,所以GET和POST的低层也是TCP/IP,也就是说GET/POST都是TCP连接。GET和POST能做的事情是一样的。GET和POST本质上就是TCP链接,并无差别,但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
GET和POST还有一个重大区别,简单的说:
GET产生一个TCP数据包 ,POST产生两个TCP数据包。
详细说:
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据)。
对于POST方式的请求,浏览器先发送header,服务器响应100,继续,浏览器再发送data,服务器响应200 (返回数据)。
理解javascript中的事件模型
一. DOM0级事件模型
DOM0级事件模型是早期的事件模型,所有的浏览器都是支持的,而且其实现也是比较简单。
<p id = 'click'>click me</p>
<script>
document.getElementById('click').onclick = function(event){
alert(event.target);
}
</script>
这种事件模型就是直接在dom对象上注册事件名称。这段代码就是在p标签上注册了一个onclick事件,在这个事件函数内部输出点击的目标。而解除事件则更加简单,就是将null复制给事件函数,如下:
document.getElementById('click'_).onclick = null;
由此可以知道dom0中,一个dom对象只能注册一个同类型的函数,因为注册多个同类型的函数,就会发生覆盖,之前注册的函数就会无效
二. DOM2级事件模型
1.事件捕获和事件冒泡
IE8及以下是不支持这种事件模型的。事件捕获和事件冒泡的机制如下图:
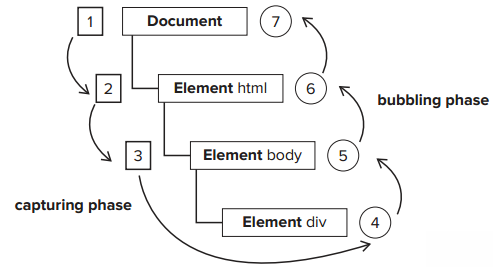
如上图所示,123代表事件捕获,4567代表事件冒泡。
2.DOM2级的注册事件和解除事件
在DOM2级中使用addEventListener和removeEventListener来注册和解除事件(IE8及之前版本不支持)。这种函数较之之前的方法好处是一个dom对象可以注册多个相同类型的事件,不会发生事件的覆盖,会依次的执行各个事件函数。
我们知道addEventListenr的第一个参数是事件名称,与DOM0级不同的是没有”on“,另外第三个参数代表捕获还是冒泡,true代表捕获事件,false代表冒泡事件。
cookie的设置和获取方法
- 设置cookie
document.cookie = 'name' + 'username' - 读取 Cookie
document.cookie - 删除 Cookie
document.cookie = "username=; expires=Thu, 01 Jan 1970 00:00:00 GMT";
JavaScript事件模型
EventUtil = {
addEventListener: function (target, type, handler) {
if (target.addEventListener()) {
target.addEventListener(type, handler);
}
else if (target.attachEvent) {
target.attachEvent('on' + type, function () {
handler.call(target)
})
}
else {
target['on' + type] = handler
}
},
removeListener : function (target, type, handler) {
if (target.removeListener) {
target.removeListener(type, handler)
}
else if (target.detachEvent) {
target.detachEvent('on' + type, handler)
}
else {
target['on' + type] = null
}
},
getEvent: function (e) {
var evt = window.event || e;
return evt;
},
getTarget: function (e) {
var evt = EventUtil.getEvent(e);
var target
if (evt.target){
target = evt.target;
}
else {
target = evt.srcElement
}
return target
},
stopPropagation: function () {
var evt = EventUtil.getEvent(e);
if (evt.stopPropagation) {
evt.stopPropagation();
}
else {
evt.cancelBubble = false;
}
},
preventDefault: function () {
var evt = EventUtil.getEvent(e);
if (evt.preventDefault) {
evt.preventDefault()
}
else {
evt.returnValue = false
}
}
}
XSS和CSRF攻击及防御
- XSS攻击(跨站脚本攻击,利用站内的信任用户)
如:url后参数带js脚本,提交表单中带js脚本到数据库中
防范:进行html转义
如 <变成< >变成> ‘变成&
jstl自带html转义,escapeMxl=”true”
防止js脚本读取cookie信息:将cookie设置成httponly
- CSRF攻击(跨站请求伪造,通过伪装受信任用户的请求)
原理:用户C访问安全站点A,A返回C一个cookie,C没退出A就访问恶意站点B,B让C访问A,此时带有cookie。A不能判断这个是恶意站点的请求,从而让B的请求得逞
- XSS和CSRF攻击的防御
XSS攻击防御:
1.对用户表单输入的数据进行过滤,对javascript代码进行转义,然后再存入数据库
2.在信息的展示页面,也要进行转义,防止javascript在页面上执行
CSRF攻击防御:
1.所有需要用户登录之后才能执行的操作属于重要操作,这些操作专递参数应该使用post方式,更加安全
2.为防止跨站请求伪造,我们在某次请求的时候都要带上一个 token参数,用于标识请求来源是否合法,token参数由系统生成,存储在session中
- SQL注入攻击
把SQL命令伪装成正常的HTTP请求参数,传递到服务器端
如:提交密码: ‘ or ‘1’=’1 或’;drop table aaa– (–注释后面的语句)
防御:
1.使用预编译语句 PreparedStatement 创建PreparedStatement对象时就发送给DBMS(数据库管理系统)进行编译,会通过参数占位符来代替参数,会把特殊字符进行转义
2.后台使用orm框架
3.对密码加密
- DDoS攻击
即分布式拒绝服务攻击
原理:通过大量计算机同时对某一主机进行访问,使主机瘫痪
如:
1.SYN Flood
因TCP三次握手中服务器得等待客户端传回ack报文,但SYN Flood伪造了大量不存在的IP进行TCP连接,使服务器瘫痪
2.DNS Query Flood
跟SYN Flood差不多,是向被攻击服务器发送海量的域名解析请求。因为这些域名都是随机生成的,在本地没有缓存,就会向上层服务器递归查询,直到全球互联网的13台根dns服务器。当解析请求超过一定量时,就会造成解析超时。
3.CC攻击
原理:通过大量计算机进行匿名HTTP代理,模拟正常用户给网站发起请求,直到拖垮后端系统,无法为正常用户提供服务
统计字符串中每种字符出现的次数,出现次数最多的是? 出现?次
var str = 'helloworld';
var hash = {};
for (var i = 0; i < str.length; i++) {
// 如果hash里面已经有这个字符那么就把这个字符的次数+1
if (hash[str[i]]) {
hash[str[i]]++
}
// 默认所有字符出现的次数都是1次
else {
hash[str[i]] = 1
}
}
标准(W3C)盒模型:元素宽度 = width + padding + border + margin 怪异(IE)盒模型:元素宽度 = width + margin
CSS 中居中的几种方式:
1.margin: 0 auto
2.text-align: center
3.绝对定位和margin: auto
4.绝对定位和transfrom
5.diplay:table-cell
6.flexBox居中
js的事件流
事件捕捉阶段 事件开始由顶层对象触发,然后逐级向下传播,直到目标元素
处于目标阶段 处在绑定事件的元素上
事件冒泡阶段 事件由具体的元素先接受,然后逐级向上传播,直到不具体的元素
页面加载过程
输入链接 浏览器查找域名IP DNS查找 浏览器缓存 - 系统缓存-路由缓存 浏览器向web服务器发送一个Http请求 服务器永久重定向响应 浏览器跟踪响应地址 服务器处理请求 服务器返回一个HTTP响应 浏览器显示HTML 浏览器发送请求获取嵌入在HTML中的资源 浏览器发送异步请求
路由器的缓存
每个路由器根据所在网络的不同,都有自己的路由表,在工作时会选择相应的路径。为什么要有路由器缓存呢,这个也是为了发送数据,因为路由器最高层一般都是网络层,网络层一般都是传送数据包,数据包又是经过应用层向下传送之后送来的一部分文件数据,如果我们没有缓存的话,那么,每次都会查找传送到达方的ip地址就会很费力。
CORS 实现思路
使用自定义的HTTP头部允许浏览器和服务器相互了解对方,从而决定请求或响应成功与否
闭包
指有权访问另一个函数作用域的函数而已。常用的创建闭包的方法就是在函数内部创建另一个函数。
http优点 基于应用级的接口使用方便 程序员开发水平要求不高,容错性强
http http所封装的信息是明文的,通过抓包工具可以分析其信息内容,如果这些信息包含有你的银行卡帐号、密码,你肯定无法接受这种服务
HTTPS的缺点: HTTPS协议的安全是有范围的,在黑客攻击、拒绝服务攻击、服务器劫持等方面几乎起不到什么作用。 最关键的,SSL 证书的信用链体系并不安全。特别是在某些国家可以控制 CA 根证书的情况下,中间人攻击一样可行。
https 完成TCP三次同步握手 客户端验证服务器数字证书,通过, DH算法协商对称加密算法的密钥、hash算法的密钥 SSL安全加密隧道协商完成 网页以加密的方式传输,用协商的对称加密算法和密匙加密,保证数据机密性,用协商的hash算法进行完整性数据保护,保证数据不被篡改
JSONP 的工作原理 就是利用
JSONP只会发一次请求 JSONP只能用于获取资源(即只读,类似于GET请求)
call、apply、bind的区别
call 和 apply 都是为了改变某个函数运行时的上下文(context)而存在的,换句话说,就是为了改变函数体内部 this 的指向。
当使用参数thisArg和argArray在对象func上调用apply方法时
bind()方法会创建一个新函数,称为绑定函数,当调用这个绑定函数时,绑定函数会以创建它时传入 bind()方法的第一个参数作为 this,传入 bind() 方法的第二个以及以后的参数加上绑定函数运行时本身的参数按照顺序作为原函数的参数来调用原函数。